Overview & Motivation
Understanding the relevance to visualization research
Paper Introduction
+Key Contribution: A framework that decomposes preferences into attribute dimensions and tailors prediction to distinct social community values.
This work addresses a fundamental challenge in AI systems: understanding and modeling user preferences at a community level rather than treating all users as homogeneous.
- Focuses on personalization through community-specific preference profiles
- Uses latent attribute modeling to understand preference dimensions
- Demonstrates significant improvements over existing approaches
Why This Matters for Visualization
+Visualization also deals with implicit preferences and needs to consider different user groups and communities.
- Implicit Preferences: Users have unstated preferences about color, layout, complexity, and interaction patterns
- Community Differences: Different professional, cultural, and demographic groups prefer different visualization approaches
- AI-Generated Visualizations: As AI becomes more involved in visualization generation, understanding preferences becomes crucial
- Personalization Challenge: Current visualization tools often use one-size-fits-all approaches
Research Question
+How can we model and predict community-specific preferences for better AI personalization?
For Visualization Context:
- How do different communities prefer their data to be visualized?
- What are the key preference dimensions in visualization design?
- Can we automatically adapt visualizations to community preferences?
- How do cultural and professional backgrounds influence visualization preferences?
PrefPalette Method
Two-stage framework for preference modeling
Data
This work models community-conditioned preferences using text from online communities and synthesized counterfactuals for attributes.
- Sources: 45 Reddit communities spanning scholarly, support, and conflict-oriented groups.
- Instance structure: community-context plus candidate responses; learning targets are community-specific preferences over candidate responses.
- Attributes: 19 total across two groups — Sociolinguistic Norms and Schwartz Cultural Values. Attribute predictors are trained using Counterfactual Attribute Synthesis.
- Learning signal: community-specific attention weights over attributes learned in Attention-based Preference Modeling.
- Evaluation: accuracy on in-domain communities and generalization to held-out communities.
Figure 2. PrefPalette Overview
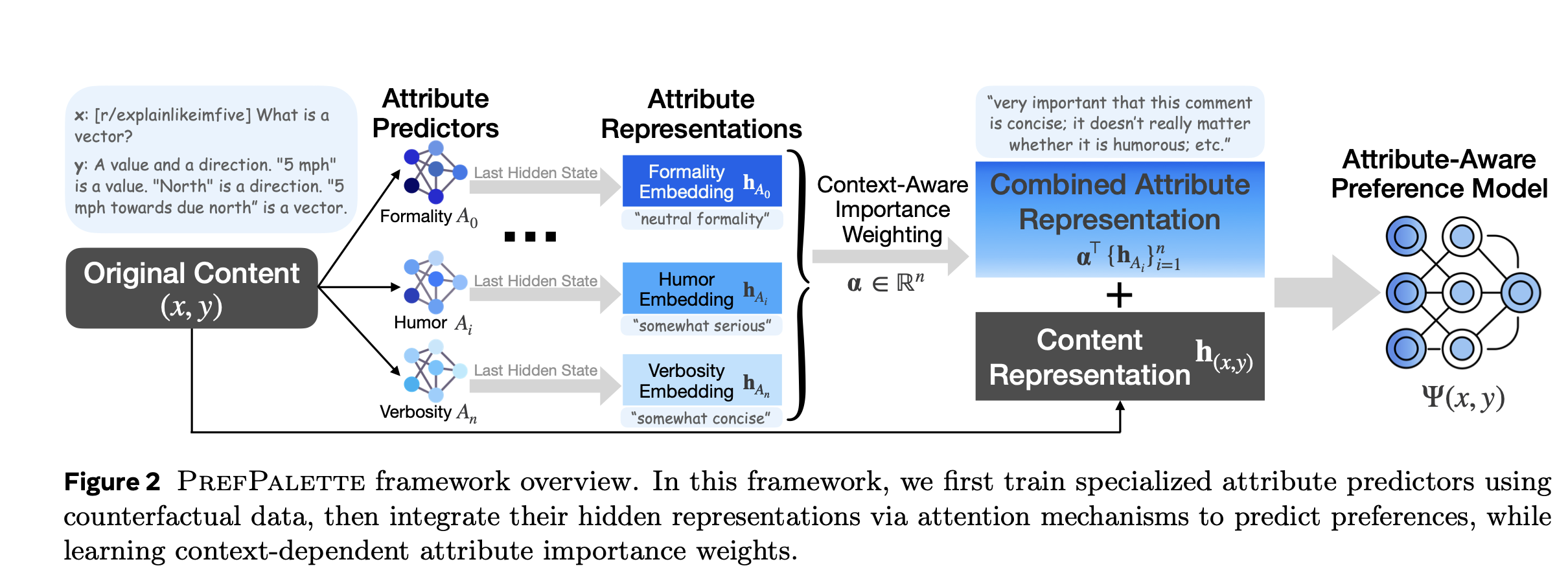
Summary diagram of the PrefPalette framework.
Preference Attributes
Sociolinguistic Norms
Schwartz Cultural Values
Multi-Attribute Decision Making
The model learns to dynamically weight different attributes based on context, allowing for nuanced preference modeling beyond simple user clustering.
- Community-specific attention weights
- Dynamic attribute combination
- Contextual preference adaptation
Key Findings
Performance results and community insights
Performance Results
Testing Scale: 45 communities on Reddit
Metric: Average prediction accuracy (Preference Prediction)
Community-Specific Preference Profiles
Scholarly Communities
Conflict-oriented Communities
Support-based Communities
Key Insights
- Community Clustering: Different communities show distinct preference patterns that can be systematically identified
- Attribute Importance: The relative importance of attributes varies significantly across communities
- Generalization: The framework successfully generalizes to unseen communities with similar characteristics
- Interpretability: Learned preference profiles provide interpretable insights into community values
Connections to Visualization
Applying preference modeling to visualization design
Target Audiences for Visualization
Different demographic categories requiring tailored visualization approaches
Visualization Preference Dimensions
Visual Complexity
Experts vs. novices prefer different levels of detail
Color Schemes
Cultural and accessibility considerations
Interaction Style
Technology familiarity affects preferred interactions
Information Density
Professional context influences data presentation preferences
Potential Applications
- AI-generated visualizations tailored to user communities
- Adaptive visualization systems that learn from user behavior
- Personalized data dashboards for different organizational roles
- Community-specific visual design patterns for different platforms
Discussion & Questions
Research opportunities and challenges
Research Questions for Our Group
How can we identify preference dimensions for visualization?
What are the equivalent of "formality," "humor," and "empathy" in the visualization domain?
What attributes matter most for different visualization tasks?
Do preferences vary between exploratory analysis, presentation, and communication tasks?
Can we build similar preference models for visualization communities?
How would we collect training data and validate community-specific preferences?
Technical Challenges
- Data Collection: How do we gather implicit preference data for visualizations?
- Preference Measurement: What metrics capture visualization preference satisfaction?
- Community Definition: How do we define and identify visualization communities?
- Generalization: Can preferences learned in one context transfer to others?
Future Research Directions
Cross-Modal Preference Transfer
Can text preferences inform visualization preferences?
Dynamic Preference Learning
Adapting to changing preferences over time and context